Добавлено в закладки: 0
 Что такое анализ кластерный – один из математических методов, заключающийся в том, что определенный набор объектов разбивают на группы, которые называются кластерами.
Что такое анализ кластерный – один из математических методов, заключающийся в том, что определенный набор объектов разбивают на группы, которые называются кластерами.
В каждом кластере объекты схожи, а меж различными кластерами существуют явные отличия. Главная цель, которую данный анализ преследует – выявить схожие объекты в исследуемой выборке.
Этот метод широко используется в разных областях человеческого знания: в биологии, психологии, медицине, химии, маркетинге, управлении и многих других дисциплинах.
Рассмотрим, более детально, что значит анализ кластерный. Кластерный анализ (англ. cluster analysis) — статистическая многомерная процедура, которая выполняет сбор данных, которые содержат информацию о выборе объектов, и потом упорядочивающая объекты в однородные сравнительно группы. Задачу кластеризации относят к статистической обработке и к широкому классу задач обучения без учителя.
Большая часть исследователей склоняется к тому, что термин «кластерный анализ» (англ. cluster — гроздь, сгусток, пучок) впервые был предложен математиком Трионом Р. В появился ряд терминов, которые принято в настоящее время считать синонимами термина «кластерный анализ»: ботриология, автоматическая классификация.
Спектр использований кластерного анализа весьма широк: его применяют в медицине, археологии, химии, психологии, государственном управлении, биологии, антропологии, филологии, социологии, маркетинге и прочих дисциплинах. Но универсальность использования вызвала появление большое количество несовместимых подходов, терминов, методов, которые затрудняют однозначное применение и непротиворечивую интерпретацию кластерного анализа.
Условия и задачи
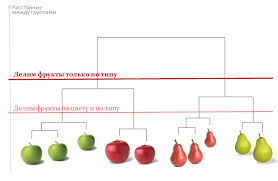 Кластерный анализ исполняет такие главные задачи:
Кластерный анализ исполняет такие главные задачи:
- Изучение концептуальных полезных схем группирования объектов.
- Разработка классификации или типологии.
- Порождение гипотез на основании исследования данных.
- Проверка исследования или гипотез для определения, действительно ли группы (типы), выделенные каким-либо методом, есть в имеющихся данных.
Вне зависимости от предмета изучения использование кластерного анализа предусматривает следующие стадии:
- Отбор выборки для кластеризации. Понимается, что есть смысл кластеризовать лишь количественные данные.
- Определение переменных, по которым будут оценивать объекты в выборке, то есть признаковое пространство.
- Вычисление значений определенной меры различия или сходства меж объектами.
- Использование способа кластерного анализа для того, чтобы создать группы сходных объектов.
- Проверка достоверности итогов кластерного решения.
Можно встретить описание двух фундаментальных требований, которые предъявляются к данным — полнота и однородность . Однородность требует, чтобы все кластеризуемые сущности были одинаковой природы, описываться похожим набором свойств. Когда кластерному анализу предшествует факторный анализ, то выборка в «ремонте» не нуждается — изложенные требования исполняются автоматически непосредственно процедурой факторного моделирования (есть ещё одно достоинство — z-стандартизация без отрицательных последствий для выборки; если её непосредственно проводить для кластерного анализа, она может за собой повлечь уменьшение чёткости разделения групп). Иначе выборку необходимо корректировать.
Типология задач кластеризации
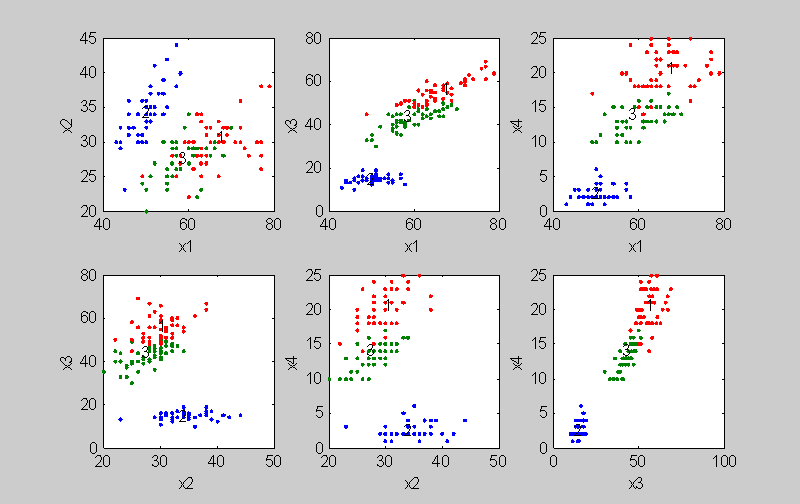 Виды входных данных
Виды входных данных
- Признаковое описание объектов. Каждый объект описывают набором собственных характеристик, которые называются признаками. Признаки могут быть нечисловыми или числовыми.
- Матрица расстояний меж объектами. Каждый объект описывают расстояниями до всех других объектов метрического пространства.
- Матрица сходства меж объектами. Учитывают степень сходства объекта с прочими объектами выборки в метрическом пространстве. Сходство тут дополняет различие (расстояние) меж объектами до 1.
В современной науке используется несколько алгоритмов обработки для входных данных. Анализ при помощи сравнения объектов, учитывая признаки, (наиболее распространённый в биологических науках) называется Q-видом анализа, а при сравнении признаков, на основании объектов — R-видом анализа. Есть попытки использовать гибридные типы анализа (к примеру, RQ-анализ), но эта методология ещё не разработана должным образом.
Цели кластеризации
- Понимание данных при помощи выявления кластерной структуры. Разбиение выборки на группы похожих объектов дает возможность упростить обработку данных в дальнейшем и принятие решений, к каждому кластеру применяя собственный метод анализа (стратегия «разделяй и властвуй»).
- Сжатие данных. Когда исходная выборка сильно большая, то можно её сократить, оставив от каждого кластера по одному самому типичному представителю.
- Обнаружение новизны (англ. novelty detection). Выделяют нетипичные объекты, которые не получается ни к одному из кластеров присоединить.
Число кластеров в первом случае стараются делать поменьше. Во втором случае более важным будет обеспечить большую степень сходства объектов в каждом кластере, а кластеров может быть сколько угодно. Наибольший интерес в третьем случае представляют отдельные объекты, которые не вписываются ни в один из кластеров.
Во всех данных ситуациях может использоваться иерархическая кластеризация, когда большие кластеры дробят на более мелкие, те дробятся в свою очередь ещё мельче, и так далее. Такие задачи называют задачами таксономии. Итог таксономии — иерархическая древообразная структура. Каждый объект при этом характеризуется перечислением кластеров, которым он принадлежит, от крупного к мелкому.
Способы кластеризации
Общепринятой классификации способов кластеризации нет, однако возможно выделить некоторые группы подходов (некоторые способы возможно отнести сразу к нескольким группам и потому предлагают рассматривать эту типизацию в качестве некоторого приближения к реальной классификации способов кластеризации):
- Вероятностный подход. Предполагают, что каждый рассматриваемый объект относят к одному из k классов. Некоторые авторы (к примеру, А. И. Орлов) полагают, что эта группа совсем не относится к кластеризации и противопоставляют её «дискриминации», то есть выбору отнесения объектов к одной известной группе (обучающим выборкам).
- Дискриминантный анализ
- K-medians
- K-средних (K-means)
- Алгоритмы семейства FOREL
- EM-алгоритм
- Подходы на основании систем искусственного интеллекта: условная группа, так как способов весьма много и они весьма различны методически.
- Генетический алгоритм
- Нейронная сеть Кохонена
- Метод нечеткой кластеризации C-средних
- Логический подход. Построение дендрограммы производится при помощи дерева решений.
- Теоретико-графовый подход.
- Графовые алгоритмы кластеризации
- Иерархический подход. Предполагают наличие вложенных групп (кластеров разного порядка). В свою очередь алгоритмы подразделяются на объединительные (агломеративные) и разделяющие (дивизивные). По числу признаков порой выделяют политетические и монотетические способы классификации.
- Таксономия или дивизивная иерархическая кластеризация. Задачи кластеризации рассматривают в числовой таксономии.
- Прочие способы, которые не вошли в прошлые группы.
- Ансамбль кластеризаторов
- Статистические алгоритмы кластеризации
- Алгоритм, который основан на способе просеивания
- Алгоритмы семейства KRAB
- DBSCAN и др.
Подходы 4 и 5 порой объединяют под названием геометрического или структурного подхода, который обладает большей формализованностью понятия близости. Невзирая на большие различия меж перечисленными способами все они опираются на начальную «гипотезу компактности»: в пространстве объектов все близкие объекты относятся к одному кластеру, а все разные объекты должны соответственно находиться в разных кластерах.
Формальная постановка задачи кластеризации
Пусть х — множество объектов, номеров (меток, имён) кластеров. Задана функция расстояния меж объектами. Есть конечная обучающая выборка объектов. Необходимо разбить выборку на непересекающиеся подмножества, которые называются кластерами, так, чтобы каждый кластер включал в себя объекты, близкие по метрике, а объекты различных кластеров значительно отличались. Каждому объекту при этом приписывают номер кластера.
Алгоритм кластеризации — функция, которая каждому объекту в соответствие ставит номер кластера. 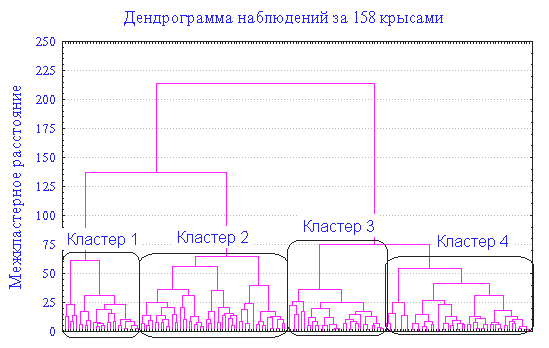 Множество в некоторых случаях заранее известно, но зачастую ставится задача определить оптимальное количество кластеров, с точки зрения определенного критерия качества кластеризации.
Множество в некоторых случаях заранее известно, но зачастую ставится задача определить оптимальное количество кластеров, с точки зрения определенного критерия качества кластеризации.
Кластеризация (обучение без учителя) от классификации (обучения с учителем) отличается тем, что метки исходных объектов вначале не заданы, и может быть даже неизвестно непосредственно множество .
Решение задачи кластеризации неоднозначно принципиально, и тому есть несколько причин (как считают некоторые):
- не существует однозначно наилучшего критерия качества кластеризации. Известен ряд эвристических критериев и ряд алгоритмов, которые не имеют выраженного чётко критерия, однако осуществляющих довольно разумную кластеризацию «по построению». Все они могут дать различные результаты. Следовательно, для того, чтобы определить качество кластеризации необходим эксперт предметной области, который сможет оценить осмысленность процесса выделения кластеров.
- количество кластеров обычно заранее неизвестно и устанавливается соответственно с некоторыми субъективными критериями. Это справедливо лишь для способов дискриминации, так как в способах кластеризации выделение кластеров происходит за счёт формализованного подхода на основании мер близости.
- Итог кластеризации в значительной степени зависит от метрики, выбор которой обычно также субъективен и его определяет эксперт. Но необходимо заметить, что есть некоторые рекомендации к выбору мер близости для разных задач.
Использование
В биологии
 Кластеризация в биологии имеет много приложений в самых различных областях. К примеру, в биоинформатике при ее помощи анализируются сложные сети взаимодействующих генов, которые состоят порой из тысяч элементов. Кластерный анализ дает возможность выделить узкие места, подсети, концентраторы и прочие скрытые свойства изучаемой системы, что в конечном счете дает возможность узнать вклад каждого гена в образование изучаемого феномена.
Кластеризация в биологии имеет много приложений в самых различных областях. К примеру, в биоинформатике при ее помощи анализируются сложные сети взаимодействующих генов, которые состоят порой из тысяч элементов. Кластерный анализ дает возможность выделить узкие места, подсети, концентраторы и прочие скрытые свойства изучаемой системы, что в конечном счете дает возможность узнать вклад каждого гена в образование изучаемого феномена.
В сфере экологии широко применяют для выделения однородных пространственно групп сообществ, организмов и так далее. Реже методы кластерного анализа применяют для исследования во времени сообществ. Гетерогенность структуры сообществ вызывает появление нетривиальных методов кластерного анализа (к примеру, метод Чекановского).
В общем, необходимо заметить, что исторически так сложилось, что в биологии в качестве мер близости чаще применяются меры сходства, а не расстояния (различия).
В социологии
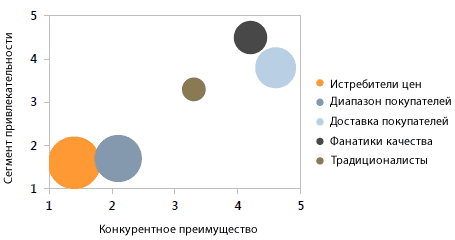 Анализируя результаты социологических исследований советуется осуществлять анализ способами агломеративного иерархического семейства, а именно способом Уорда, при котором в кластерах оптимизируют минимальную дисперсию, в результате создаются кластеры приблизительно одинаковых размеров. Способ Уорда наиболее удачным является для анализа социологических данных. Как мера отличия лучше квадратичное евклидово расстояние, которое дает возможность увеличить контрастность кластеров. Главным результатом иерархического кластерного анализа является «сосульчатая диаграмма» или дендрограмма. Исследователи при её интерпретации сталкиваются с проблемой аналогичного рода, что и толкование итогов факторного анализа — отсутствие однозначных критериев для выделения кластеров. Как главные, рекомендуется применять два метода — визуальный анализ дендрограммы и сравнение итогов кластеризации, которая выполнена разными методами.
Анализируя результаты социологических исследований советуется осуществлять анализ способами агломеративного иерархического семейства, а именно способом Уорда, при котором в кластерах оптимизируют минимальную дисперсию, в результате создаются кластеры приблизительно одинаковых размеров. Способ Уорда наиболее удачным является для анализа социологических данных. Как мера отличия лучше квадратичное евклидово расстояние, которое дает возможность увеличить контрастность кластеров. Главным результатом иерархического кластерного анализа является «сосульчатая диаграмма» или дендрограмма. Исследователи при её интерпретации сталкиваются с проблемой аналогичного рода, что и толкование итогов факторного анализа — отсутствие однозначных критериев для выделения кластеров. Как главные, рекомендуется применять два метода — визуальный анализ дендрограммы и сравнение итогов кластеризации, которая выполнена разными методами.
Визуальный анализ дендрограммы предусматривает «обрезание» дерева на оптимальном уровне сходства элементов выборки. «Виноградную ветвь» (терминология Олдендерфера М. С. и Блэшфилда Р. К.) целесообразно «обрезать» на отметке 5 шкалы Rescaled Distance Cluster Combine, тогда будет достигнут 80 % уровень сходства. Когда выделение кластеров по данной метке затрудняется (на ней происходит слияние нескольких маленьких кластеров в один большой), то можно другую метку выбрать. Такую методику предлагает Олдендерфер и Блэшфилд.
Тогда появляется вопрос устойчивости принятого кластерного решения. По сути, проверку устойчивости кластеризации сводят к проверке её достоверности. Тут есть эмпирическое правило — устойчивая типология сберегается при изменении способов кластеризации. Итоги кластерного иерархическогоанализа возможно проверять кластерным итеративным анализом по методу k-средних. Когда сравниваемые классификации групп респондентов имеют долю совпадений больше 70 % (больше 2/3 совпадений), кластерное решение принимают.
Проверить адекватность решения, не вызывая помощь другого типа анализа, нельзя. В теоретическом плане, по крайней мере, данная проблема не решена. В классической работе Блэшфилда и Олдендерфера «Кластерный анализ» детально рассматриваются и в результате отвергаются добавочные пять способов проверки устойчивости:
- методы Монте-Карло весьма сложны и доступны лишь опытным математикам;
- тесты значимости (дисперсионный анализ) — дают всегда значимый результат;
- кофенетическая корреляция — не советуется и в использовании ограниченна;
- тесты значимости для внешних признаков являются пригодными лишь для повторных измерений;
- методика случайных (повторных) выборок, что всё-таки не доказывает обоснованность решения.
В информатике
 Кластеризация итогов поиска — применяется для «интеллектуальной» группировки итогов при поиске веб-сайтов, файлов, прочих объектов, предоставляя пользователю возможность для быстрой навигации, исключения заведомо менее релевантного подмножества и выбора более релевантного — что может увеличить юзабилити интерфейса в сравнении с выводом в виде простого списка, который сортируется по релевантности.
Кластеризация итогов поиска — применяется для «интеллектуальной» группировки итогов при поиске веб-сайтов, файлов, прочих объектов, предоставляя пользователю возможность для быстрой навигации, исключения заведомо менее релевантного подмножества и выбора более релевантного — что может увеличить юзабилити интерфейса в сравнении с выводом в виде простого списка, который сортируется по релевантности.
- Clusty — поисковая кластеризующая машина компании Vivísimo
- Nigma — поисковая российская система с автоматической кластеризацией итогов
- Quintura — визуальная кластеризация, как облака ключевых слов
- Сегментация изображений — кластеризацию можно использовать для разбиения цифрового изображения на отдельные области для распознавания объектов и обнаружения границ.
- Интеллектуальный анализ данных — кластеризация в Data Mining имеет ценность тогда, когда она выступает одним из стадий анализа данных, построения завершившегося аналитического решения. Аналитику зачастую легче выделить группы похожих объектов, изучить их особенности и для каждой группы построить отдельную модель, нежели создавать для всех данных одну общую модель. Таким приемом пользуются постоянно в маркетинге, выделяя группы товаров, покупателей, клиентов и разрабатывая отдельную стратегию для каждой из них.
Мы надеемся, что дали наиболее полное определение и понятие термина анализ кластерный, раскрыли его использование. Оставляйте свои комментарии или дополнения к материалу

 Анализ ликвидности баланса
Анализ ликвидности баланса Аналитик
Аналитик Анализ ликвидности предприятия
Анализ ликвидности предприятия Анализ портфельный
Анализ портфельный Анализ функционально-стоимостной
Анализ функционально-стоимостной Акционирование
Акционирование Акция
Акция Аллокация
Аллокация Амортизационный фонд
Амортизационный фонд Амортизация основных средств
Амортизация основных средств Альтернативная стоимость
Альтернативная стоимость Анализ горизонтальный
Анализ горизонтальный Амортизационные отчисления
Амортизационные отчисления Аллонж
Аллонж Амортизация нематериальных активов
Амортизация нематериальных активов Акционерный капитал
Акционерный капитал Активы чистые
Активы чистые Акцептовать
Акцептовать Акционер
Акционер Актуарные расчеты
Актуарные расчеты Акцептант
Акцептант Активы финансовые
Активы финансовые

















Мне нравиться статья она очень содержательная и хочу узнать побольше